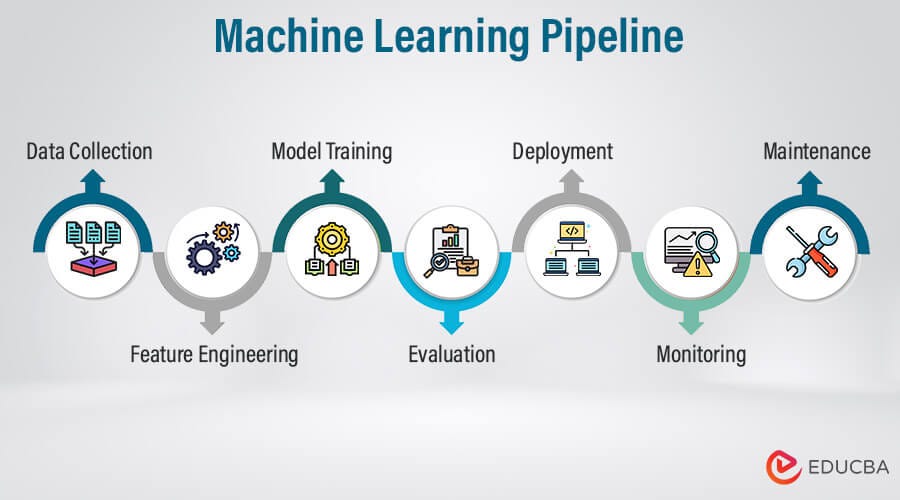

머신러닝이란 무엇인가, 왜 지금 더 중요해졌을까
머신러닝은 컴퓨터가 규칙을 외우는 대신, 데이터 속에서 스스로 기준을 만들어가는 방법이다.
사람이 모든 경우를 예상해 코드를 짜던 방식에서 벗어나,
경험을 통해 판단이 조금씩 나아지는 구조를 가진다.
그래서 머신러닝은 기술이라기보다
학습 방식에 가깝다.
컴퓨터는 원래 계산만 잘하는 존재였다
기존 프로그램은 명확했다.
조건이 있고, 그 조건을 만족하면 결과가 나온다.
문제는 세상이 그렇게 단순하지 않다는 데 있다.
사람의 말투, 사진의 분위기, 고객의 취향처럼
딱 잘라 말하기 어려운 문제들은
규칙으로 표현하는 순간 한계가 생긴다.
이 지점에서 머신러닝이 등장했다.
머신러닝의 핵심은 규칙이 아니라 데이터다
머신러닝은 이렇게 생각한다.
“정답을 알려줄 테니,
그 정답이 나오게 만든 공통점을 찾아봐.”
컴퓨터는 수많은 데이터를 비교하며
사람이 인식하지 못하는 미세한 패턴까지 학습한다.
이 과정에서 만들어지는 것이 바로 모델이다.
이 모델이 이후 새로운 데이터를 보고
예측과 판단을 수행한다.
머신러닝은 어떻게 학습할까
지도 학습은 문제와 정답을 함께 준다.
시험 문제를 풀면서 채점받는 것과 비슷하다.
이미지 분류, 가격 예측, 스팸 분류가 여기에 속한다.
비지도 학습은 정답 없이 데이터를 관찰한다.
비슷한 것끼리 묶고, 구조를 찾아낸다.
고객 군집 분석이나 패턴 탐색에 쓰인다.
강화 학습은 행동의 결과로 배우는 방식이다.
잘하면 보상을 받고, 못하면 불이익을 받는다.
게임 AI나 자동화 시스템에서 많이 활용된다.
왜 머신러닝이 각광받을까
첫째, 데이터가 넘쳐나기 시작했다.
둘째, 컴퓨팅 성능이 비약적으로 좋아졌다.
셋째, 사람의 판단을 자동화해야 할 영역이 늘어났다.
이 세 가지가 겹치면서
머신러닝은 실험적인 기술이 아니라
현실적인 선택지가 되었다.
머신러닝의 오해 하나
머신러닝이 모든 걸 알아서 해주지는 않는다.
데이터가 나쁘면 결과도 나쁘고,
학습하지 않은 영역에서는 쉽게 틀린다.
결국 중요한 건
어떤 데이터를 쓰고,
어떤 문제를 풀게 할 것인가다.
정리하며
머신러닝은
컴퓨터에게 생각을 가르치는 기술이 아니라,
경험하는 법을 가르치는 방법이다.
그래서 머신러닝을 이해한다는 건
알고리즘보다 먼저
데이터와 문제를 바라보는 관점을 바꾸는 일이다.