728x90
반응형


운영하다 보면 이런 상황 자주 만나지:
- 서버마다 로그 포맷이 다 다름
- Kubernetes, WAS, DB 로그가 여기저기 흩어져 있음
- 장애 분석하려면 파일 직접 뒤져야 함
이걸 한 번에 해결해주는 게 바로 Logstash야.
✅ Logstash 한 줄 정의
Logstash는 여러 시스템에서 들어오는 로그·이벤트 데이터를 수집(Input) → 가공(Filter) → 저장소나 분석 시스템으로 전달(Output)하는 데이터 파이프라인 엔진이다.
보통 아래 조합으로 많이 사용돼:
- Elasticsearch (저장 & 검색)
- Kibana (대시보드 시각화)
이 세 가지를 묶어서 Elastic Stack이라고 불러.
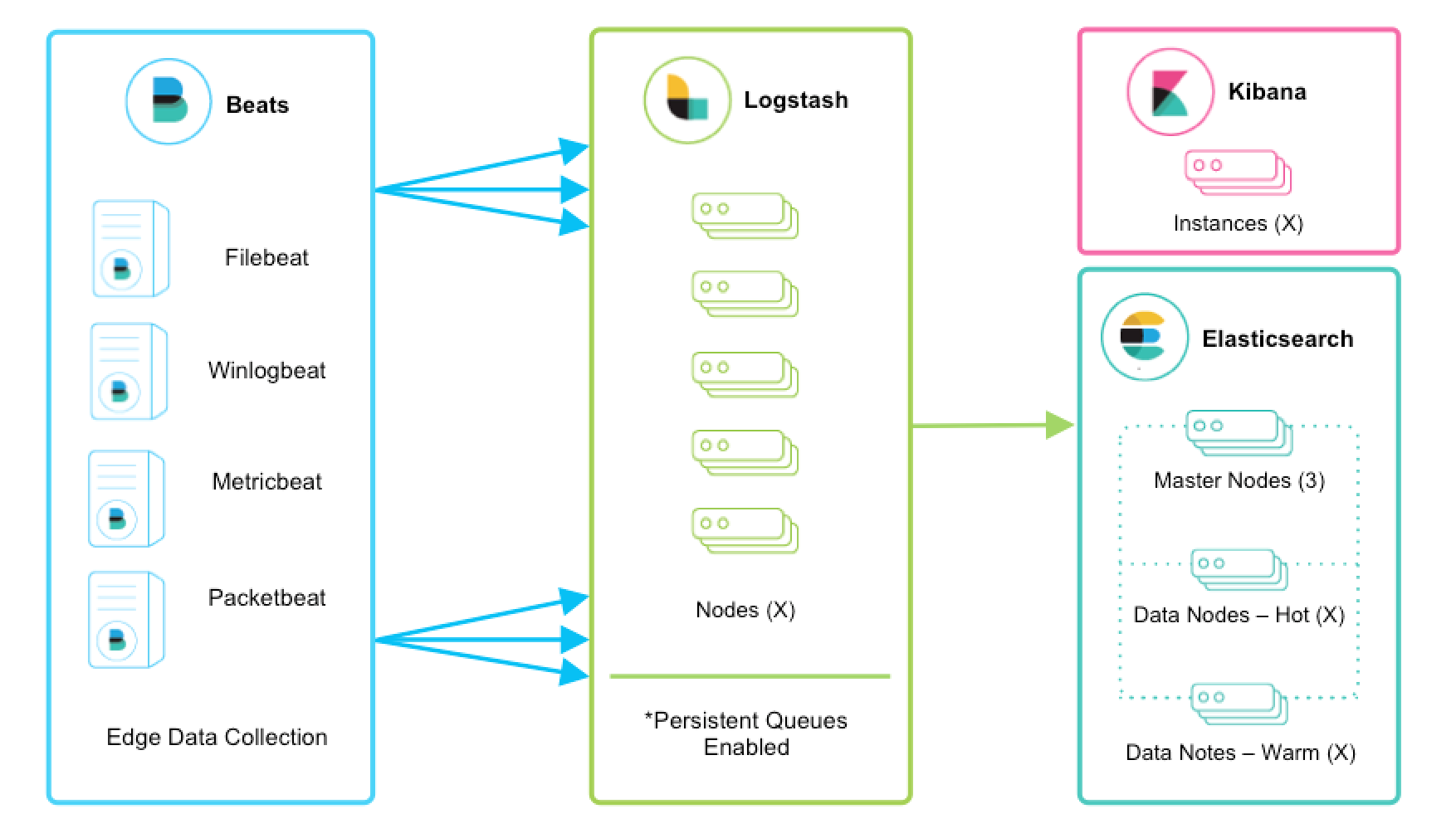
🔄 Logstash 구조 (Input → Filter → Output)
1️⃣ Input – 데이터 수집
다양한 소스에서 로그를 받아:
- 파일 로그
- syslog
- HTTP
- Kafka
- Beats
예:
nginx access log
application log
k8s container log2️⃣ Filter – 파싱 & 변환 (핵심 구간)
여기가 Logstash의 꽃이야.
대표 필터:
- grok → 문자열 파싱
- mutate → 필드 수정
- json → JSON 변환
- date → timestamp 정규화
예를 들면:
"GET /index.html 200"이걸
method=GET
uri=/index.html
status=200처럼 구조화된 필드 데이터로 바꿔줘.
3️⃣ Output – 목적지로 전송
가공된 데이터는 보통 여기로 보내:
- Elasticsearch
- S3
- File
- Kafka
가장 흔한 운영 구조:
Logstash → Elasticsearch → Kibana🧱 Elastic Stack 안에서 Logstash 역할
실무에서는 이런 흐름이야:
Beats → Logstash → Elasticsearch → Kibana정리하면:
- Beats : 로그 수집기
- Logstash : 로그 가공 공장
- Elasticsearch : 검색 DB
- Kibana : 모니터링 화면
Logstash는 딱 중앙 정제 허브 역할.
✅ 왜 굳이 Logstash를 쓰는가?
✔ 로그 포맷 통합
서버마다 다른 로그 → 하나의 스키마로 변환
✔ 실시간 처리
스트리밍 방식 지원
✔ 복잡한 파싱 가능
grok 기반 정교한 패턴 매칭
✔ 멀티 전송
여러 output 동시 지원
🧠 아주 쉽게 비유하면
Logstash는 로그 세탁소
- 더러운 원본 로그를 받아서
- 규격 맞게 빨고 정리해서
- Elasticsearch라는 옷장에 넣어주는 역할.
📌 정리
항목설명
| Logstash | 로그 수집·가공·전송 파이프라인 |
| 핵심 구조 | Input → Filter → Output |
| 주 사용처 | Elasticsearch 연계 |
| 강점 | 실시간 처리 + 강력한 파싱 |
| 위치 | Elastic Stack 중앙 |
728x90
반응형