728x90
반응형
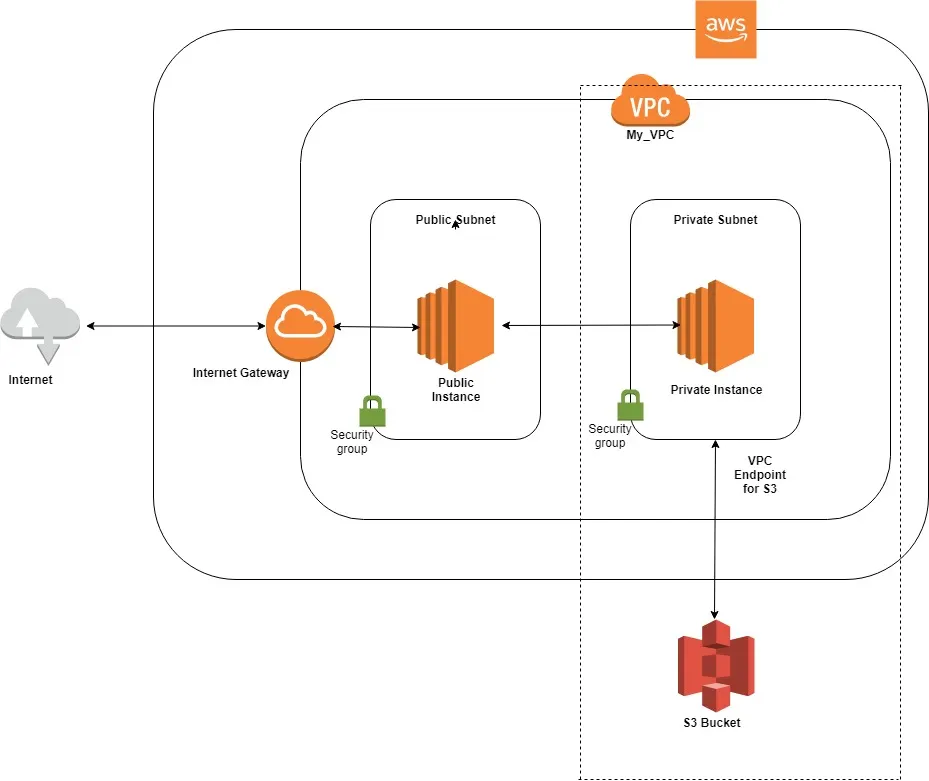

서버를 운영하다 보면 반드시 한 번쯤 마주치는 에러가 있습니다.
바로 503 Service Unavailable 입니다.
이 글에서는 503 에러의 정확한 의미, 실제 현장에서 발생하는 대표 원인, 그리고 AWS·Kubernetes 환경 기준 실전 트러블슈팅 순서까지 정리해드립니다.
✅ 503 에러 한 줄 정의
503은 서버가 죽은 상태가 아니라, “지금은 요청을 처리할 수 없는 상태”를 의미합니다.
즉,
- 서버 프로세스는 살아있음
- 네트워크도 정상
- 하지만 과부하 / 점검 / 의존 서비스 장애 등으로 응답 불가
👉 쉽게 말해:
“잠깐만요. 지금 너무 바쁩니다.”
🔍 503 에러가 발생하는 대표적인 이유
1. 트래픽 과부하
가장 흔한 케이스입니다.
- 갑작스러운 사용자 폭증
- 카드 승인 / 토큰 발급 요청 집중
- 배치 작업 몰림
결과적으로:
- CPU 100%
- Memory 부족
- Connection exhaustion
이 되면 애플리케이션이 503을 반환합니다.
2. 서버 재시작 / 배포 중
아래 상황에서 자주 발생합니다.
- WAS rolling restart
- Pod 교체
- Auto Scaling scale-in/out
- 무중단 배포 설정 미흡
헬스체크 통과 전 요청이 들어오면 바로 503입니다.
3. Load Balancer 뒤 Target 전부 unhealthy
운영에서 꽤 위험한 상태입니다.
- Target Group 전체 down
- Kubernetes Pod 전부 crash
- Readiness probe 실패
이 경우 LB는 보낼 곳이 없어서 503을 리턴합니다.
4. DB / Redis / 외부 API 장애
서버 자체는 살아있지만:
- DB connection hang
- Redis timeout
- 외부 카드사 API 지연
이런 dependency 장애가 발생하면 애플리케이션 레벨에서 503을 직접 뱉습니다.
⚔️ 500 에러와 503 에러 차이
많이 헷갈리는 부분이라 표로 정리합니다.
구분의미
| 500 Internal Server Error | 서버 내부 로직 오류 (버그, 예외) |
| 503 Service Unavailable | 서버는 정상이나 현재 처리 불가 |
핵심 요약
- 500 = “내가 잘못했어”
- 503 = “지금은 힘들어”
운영 관점에서 접근 방식이 완전히 다릅니다.
🛠 실무 기준 503 발생 시 체크 순서 (AWS / K8S)
현장에서 바로 쓰는 흐름입니다.
✅ 1단계 — 인프라 생존 확인
- ALB Target health
- Pod / EC2 alive 여부
✅ 2단계 — 리소스 상태
- CPU
- Memory
- Connection 수
- Thread pool
✅ 3단계 — Dependency
- DB connection
- Redis latency
- Kafka lag
✅ 4단계 — 최근 변경 이력
- 직전 배포
- Auto Scaling 이벤트
- 보안 정책 변경
- 네트워크 수정
📌 운영자가 기억해야 할 핵심
503은 단순 에러가 아니라 “시스템이 버티는 마지막 신호”입니다.
따라서:
- 단순 재시작 ❌
- 원인 분석 없이 스케일만 증가 ❌
반드시:
👉 트래픽
👉 리소스
👉 의존 서비스
👉 최근 변경사항
을 같이 봐야 합니다.
✨ 마무리 요약
- 503은 서버 다운이 아님
- 과부하 / 점검 / 의존 장애 신호
- 500과 완전히 다른 성격
- 운영에서는 구조적으로 접근해야 함
503 Service Unavailable 에러란? 운영자가 꼭 알아야 할 원인과 실전 대응 방법
이 글에서는 503 에러의 정확한 의미, 실제 현장에서 발생하는 대표 원인, 그리고 AWS·Kubernetes 환경 기준 실전 트러블슈팅 순서까지 정리해드립니다.
✅ 503 에러 한 줄 정의즉,- 서버 프로세스는 살아있음
- 네트워크도 정상
- 하지만 과부하 / 점검 / 의존 서비스 장애 등으로 응답 불가
🔍 503 에러가 발생하는 대표적인 이유가장 흔한 케이스입니다.- 갑작스러운 사용자 폭증
- 카드 승인 / 토큰 발급 요청 집중
- 배치 작업 몰림
- CPU 100%
- Memory 부족
- Connection exhaustion
2. 서버 재시작 / 배포 중- WAS rolling restart
- Pod 교체
- Auto Scaling scale-in/out
- 무중단 배포 설정 미흡
3. Load Balancer 뒤 Target 전부 unhealthy- Target Group 전체 down
- Kubernetes Pod 전부 crash
- Readiness probe 실패
4. DB / Redis / 외부 API 장애- DB connection hang
- Redis timeout
- 외부 카드사 API 지연
⚔️ 500 에러와 503 에러 차이구분의미
핵심 요약500 Internal Server Error 서버 내부 로직 오류 (버그, 예외) 503 Service Unavailable 서버는 정상이나 현재 처리 불가 - 500 = “내가 잘못했어”
- 503 = “지금은 힘들어”
🛠 실무 기준 503 발생 시 체크 순서 (AWS / K8S)
✅ 1단계 — 인프라 생존 확인- ALB Target health
- Pod / EC2 alive 여부
✅ 2단계 — 리소스 상태- CPU
- Memory
- Connection 수
- Thread pool
✅ 3단계 — Dependency- DB connection
- Redis latency
- Kafka lag
✅ 4단계 — 최근 변경 이력- 직전 배포
- Auto Scaling 이벤트
- 보안 정책 변경
- 네트워크 수정
📌 운영자가 기억해야 할 핵심따라서:- 단순 재시작 ❌
- 원인 분석 없이 스케일만 증가 ❌
✨ 마무리 요약- 503은 서버 다운이 아님
- 과부하 / 점검 / 의존 장애 신호
- 500과 완전히 다른 성격
- 운영에서는 구조적으로 접근해야 함
- 👉 트래픽
👉 리소스
👉 의존 서비스
👉 최근 변경사항 - 503은 단순 에러가 아니라 “시스템이 버티는 마지막 신호”입니다.
- 현장에서 바로 쓰는 흐름입니다.
- 많이 헷갈리는 부분이라 표로 정리합니다.
- 서버 자체는 살아있지만:
- 운영에서 꽤 위험한 상태입니다.
- 아래 상황에서 자주 발생합니다.
- 1. 트래픽 과부하
- “잠깐만요. 지금 너무 바쁩니다.”
- 503은 서버가 죽은 상태가 아니라, “지금은 요청을 처리할 수 없는 상태”를 의미합니다.
- 서버를 운영하다 보면 반드시 한 번쯤 마주치는 에러가 있습니다.
바로 503 Service Unavailable 입니다. 


728x90
반응형